Health Science Journal
Klíčová slova
Digitální ukládání dat; kyselina deoxyribonukleová (DNA); binární; kódování; dekódování; sekvenování
Úvod
Dnes je výbušná doba velkých dat. Tato velká data existují a pokrývají téměř všude, od obchodů s potravinami po banky, od offline po online, od akademie po průmysl, od nemocnice po komunitu, od organizace po vládu. Ukládání a správa velkých dat se stává vážným problémem. V současné době je většina dat na celém světě uložena především na magnetických a optických médiích, jako jsou HDD (pevné disky), DISKY, CD, pásky, DVD, přenosné pevné disky a USB streak disky . Rychlost růstu těchto archivních dat se však exponenciálně zvyšuje. Tato tradiční média a jejich omezená kapacita pro ukládání dat nemohou splnit požadavek rychlého nárůstu digitálních dat. Současně je jednou z hlavních výzev trvanlivost těchto médií pro ukládání dat. Jejich trvanlivost je velmi omezená. Tato média vydrží jen velmi omezenou dobu. Například disky vydrží několik let a pásky několik desetiletí. Jiná elektronická úložiště lze v dobrém stavu uchovávat po několik desetiletí. Dalším problémem pro ukládání velkých digitálních dat je kapacita pro ukládání dat. Na CD může být uloženo několik set megabajtů (MB) dat. Velký pevný disk může uchovávat několik terabajtů (TB) dat. Jejich kapacita však zdaleka nedosahuje požadavků na explozivní informační data .
Jak uvedl Patrizio, v roce 2018 je na světě celkem 33 zettabajtů (ZBs) dat (https://www.networkworld.com), což se rovná 22 bilionům gigabajtů (GBs). Proto je zapotřebí nová technologie ukládání a inovativní systém, který by splňoval požadavky této moderní doby. Očekává se, že deoxyribonukleová kyselina (DNA) bude díky svým jedinečným výhodám ideálním médiem pro ukládání digitálních dat . Ukládání digitálních dat do DNA není novinkou. Ve skutečnosti jej popsal sovětský fyzik Michail Neiman v roce 1960 (https:// www.geneticsdigest.com). Poprvé však bylo prokázáno, že DNA může ukládat digitální data, v roce 1988 . Zde nejprve představíme aplikace DNA jako nového média pro ukládání digitálních dat a dále se budeme zabývat podrobnějšími informacemi v této oblasti DNA sloužící jako médium pro ukládání dat.
Přehled předchozích studií
Dvojková číselná soustava
Počítače a další digitální elektronická zařízení ukládají data a pracují s dvojkovou číselnou soustavou, která používá pouze dvě digitální čísla neboli 0 a 1 . Texty se v počítačové soustavě převádějí na binární verzi. Počítače zase pracují a počítají ve dvojkové soustavě, případně převádějí informace na čitelné texty. Jeden bajt obsahuje osm bitů složených z 0 nebo 1 a má 28 (256) možných hodnot (od 0 do 255) a ukládá jedno písmeno (obrázek 1 a tabulka 1) . Jak ukazuje převodní tabulka ASCII (tabulka 1). Dvacet šest písmen s velkými a malými písmeny se převádí mezi písmeny, dvojkovou a šestnáctkovou soustavou. Pro uložení velkého souboru nebo dokumentu je potřeba mnohem více dat v paměti. Běžná skladba může potřebovat desítky megabajtů, pro uložení filmu několik gigabajtů a pro knihy uložené ve velké knihovně několik terabajtů. Jak ukazuje tabulka 2, jsou velikosti měření a paměti pro použití dvojkové soustavy od nejmenší jednotky „bajt“ až po velké jednotky, včetně bajtu (B), kilobajtu (KB), megabajtu (MB), gigabajtu (GB), terabajt (TB), pegabajt (PB), exabajt (EB), zettabajt (ZB), yottabajt (YB), brontobajt (BB), geobajt (GPB) a tak dále (https://www.geeksforgeeks.org&https://whatsabyte.com). Jednotky jako brontobyte (BB), geopbyte (GPB) jsou nepředstavitelně obrovské hodnoty, které se v našem reálném světě možná nikdy nepoužijí (tabulka 2).

Obrázek 1: Textový řetězec „DNA digital data storage“ byl převeden jako binární bity.
Table 1: The conversion ASCII table of the twenty-six letters with the upper and lower cases among letter, binary and hexadecimal.
| Letter | Binary | Hexadecimal | Letter | Binary | Hexadecimal |
|---|---|---|---|---|---|
| A | 1000001 | 41 | a | 1100001 | 61 |
| B | 1000010 | 42 | b | 1100010 | 62 |
| C | 1000011 | 43 | c | 1100011 | 63 |
| D | 1000100 | 44 | d | 1100100 | 64 |
| E | 1000101 | 45 | e | 1100101 | 65 |
| F | 1000110 | 46 | f | 1100110 | 66 |
| G | 1000111 | 47 | g | 1100111 | 67 |
| H | 1001000 | 48 | h | 1101000 | 68 |
| I | 1001001 | 49 | i | 1101001 | 69 |
| J | 1001010 | 4A | j | 1101010 | 6A |
| K | 1001011 | 4B | k | 1101011 | 6B |
| L | 1001100 | 4C | l | 1101100 | 6C |
| M | 1001101 | 4D | m | 1101101 | 6D |
| N | 1001110 | 4E | n | 1101110 | 6E |
| O | 1001111 | 4F | o | 1101111 | 6F |
| P | 1010000 | 50 | p | 1110000 | 70 |
| Q | 1010001 | 51 | q | 1110001 | 71 |
| R | 1010010 | 52 | r | 1110010 | 72 |
| S | 1010011 | 53 | s | 1110011 | 73 |
| T | 1010100 | 54 | t | 1110100 | 74 |
| U | 1010101 | 55 | u | 1110101 | 75 |
| V | 1010110 | 56 | v | 1110110 | 76 |
| W | 1010111 | 57 | w | 1110111 | 77 |
| X | 1011000 | 58 | x | 1111000 | 78 |
| Y | 1011001 | 59 | y | 1111001 | 79 |
| Z | 1011010 | 5A | z | 1111010 | 7A |
*Note: ACSII (American Standard Code for Information Interchange): serial digital codes to represent number, letters, numerals, and other symbols and to be used as a standard format in the computer system.
Table 2: The sizes of measurement and memory.
| Sizes | Byte Magnitude | Units | Storage* |
|---|---|---|---|
| 1 B | 100 | Byte | A character „A“, „1“, „$“ |
| 10 B | 101 | ||
| 100 B | 102 | ||
| 1 KB | 103 | Kilo byte | The size for graphics of small websites ranges between 5 and 100 KB |
| 10 KB | 104 | ||
| 100 KB | 105 | ||
| 1 MB | 106 | Mega byte ( 1 MB: 1 million) |
The size for a high resolution JPEG image is about 1-5 MB |
| 10 MB | 107 | The size for a 3-minute song is about 30 MB | |
| 100 MB | 108 | ||
| 1 GB | 109 | Giga byte | The size for a standard DVD drive is about 5 GB |
| 10 GB | 1010 | (1 GB: 1 billion) | |
| 100 GB | 1011 | ||
| 1 TB | 1012 | Tera byte (1 TB: 1 trillion) |
The size for a typical internal HDD is about 2 TB |
| 10 TB | 1013 | ||
| 100 TB | 1014 | ||
| 1 PB | 1015 | Peta byte (1 PB: 1 quadrillion) |
Google store over 100 PB of all data in their drivers. |
| 10 PB | 1016 | ||
| 100 PB | 1017 | ||
| 1 EB | 1018 | Exa byte (1 EB: 1 quintillion) |
Several hundred EBs of data are transferred over global internet per year Facebook built an entire data center to store 1 EB of data in 2013 |
| 10 EB | 1019 | ||
| 100 EB | 1020 | ||
| 1 ZB | 1021 | Zetta byte (1 ZB: 1 sextillion) |
33 ZBs of global data in 2018. 160-180 ZBs of data is predicted in 2025. |
| 10 ZB | 1022 | ||
| 100 ZB | 1023 | ||
| 1 YB | 1024 | Yotta byte (1 YB: 1 septillion) |
1YB = 1 million EBs 1 YB = Size of the entire World Wide Web |
| 10 YB | 1025 | ||
| 100 YB | 1026 | ||
| 1 BB | 1027 | Bronto byte (1 BB: 1 octillion) |
1BB equals to 1 million ZBs The only thing there is to say about a Brontobyte is that it is a 1 followed by 27 zeros! |
| 10 BB | 1028 | ||
| 100 BB | 1029 | ||
| 1 GPB | 1030 | Geop byte (1 GPB: 1 nonillion) | 1, No one knows why this term was created. It is highly doubtful that anyone alive today will EVER see a Geopbyte hard drive. |
The digital data storage
Digital Data Storage (DDS) was introduced and developed in 1980s. It is a computer-based data storage technology that is based on the Digital Audio Tape (DAT) format. These digital data were stored on the silicon-based chips. Silicon is the primary material of most semiconductor and microelectronic chips. Čistý paměťový křemík se v přírodě vyskytuje jen zřídka. Očekává se, že všechny zásoby křemíku pro mikročipy na světě v blízké budoucnosti dojdou. Také Moorův zákon (Počet tranzistorů umístěných na integrovaných obvodech se každé dva roky téměř zdvojnásobí, neboli čipy s větším počtem tranzistorů běží rychleji) se blíží ke konci . Čipy tedy nemohou pojmout další tranzistory a dosáhnou hranice své kapacity.
Momentálně je většina současných digitálních dat uložena na tradičních magnetických, optických a dalších médiích, jako jsou HDD (pevné disky) a CD. Kromě omezené kapacity pro ukládání dat lze tato média uchovávat také po velmi omezenou dobu . Jsou citlivá na prostředí nebo podmínky ukládání dat. Jakákoli změna prostředí a podmínek, jako je magnetické působení, vysoká vlhkost, vysoká teplota, mechanické poškození, může případně vést k poškození těchto médií nebo ke ztrátě jejich dat. A časté používání také může vést k jejich poškození nebo ztrátě dat. A také pro uložení velkého množství dat a splnění požadavku na explozivní nárůst dat potřebujeme velké množství takových médií, jako jsou disky, CD, DVP, pevné disky. Ty vedou k vysokým nákladům a jsou časově náročné.
Současně exponenciálně roste nárůst digitálních dat a požadavek na jejich ukládání. Společnost IBM vybudovala v roce 2011 velké centrum s kapacitou ukládání dat 120 PB. Společnost Facebook postavila v roce 2013 další větší centrum s kapacitou ukládání 1 EB (1000 PBs) dat. Všichni uživatelé digitálních technologií na celém světě vyprodukovali denně více než 44 exabajtů (EB) (44000 PBs) dat. V roce 2010 byl celosvětově vyprodukován celkem 1 zetabajt (ZB, 1000 EBs nebo 1 milion PBs) dat, v roce 2018 to bylo 33 zetabajtů (ZB) dat a v roce 2025 se předpokládá 150-200 zetabajtů (ZBs) (citováno z webu Datanami: https:// www.datanami.com a webu Network world: https:// www.networkworld.com) . K uložení těchto dat by byly potřeba stovky tisíc obrovských prostorových center. V roce 2018 měl Facebook celkem 15 datových center a další nová centra byla ohlášena. V Nebrasce postaví další čtyři datová centra, která se budou skládat ze šesti velkých budov s plochou pro ukládání dat přesahující 2,6 milionu čtverečních stop. Ať už je to jakkoli, datové prostory nikdy nemohou zachytit exponenciální nárůst dat. Současná paměťová média také nemohou uspokojit požadavky na ukládání dat. Je naléhavě nutné vyvinout novou generaci technologie ukládání dat namísto současného ukládání dat na bázi křemíku. Díky svým jedinečným vlastnostem a potenciálním výhodám se deoxyribonukleová kyselina (DNA) jako možné digitální médium pro ukládání dat dostává do ústřední fáze ukládání dat.
Základní informace o deoxyribonukleové kyselině (DNA)
V roce 1953 Dr. Crick a Watson odhalili, že molekula DNA má dvojitá vlákna, která se kolem sebe stáčejí a tvoří dvojitou šroubovici. Obecně jsou genetické materiály ve většině přírodních organismů tvořeny dvojitými vlákny šroubovice DNA, přičemž některé jsou tvořeny jedním vláknem DNA a některé další jsou tvořeny jedním nebo dvěma vlákny RNA. Složky DNA neboli nukleotidy se skládají z dusíkatých bází, fosfátových skupin a deoxyribózových skupin. Dvě písmena jsou strukturována jako páteř každé molekuly DNA, přičemž každý pár bází z každého vlákna se spojuje vodíkovou vazbou. Nukleotidy DNA se skládají ze čtyř typů bází včetně adeninu (A), cytosinu (C), guaninu (G) a thyminu (T) (obrázek 2) , přičemž ribonukleová kyselina (RNA) má čtyři typy bází včetně adeninu (A), cytosinu (C), guaninu (G) a uracilu (U) místo thyminu (T). Adenin (A) a guanin (G) jsou puriny, cytosin (C), tymin (T) a uracil (U) jsou pyrimidiny . In DNA molecules, the base-pairing rule is that A pairs with T, and G pairs with C (Figures 3 and 4) .
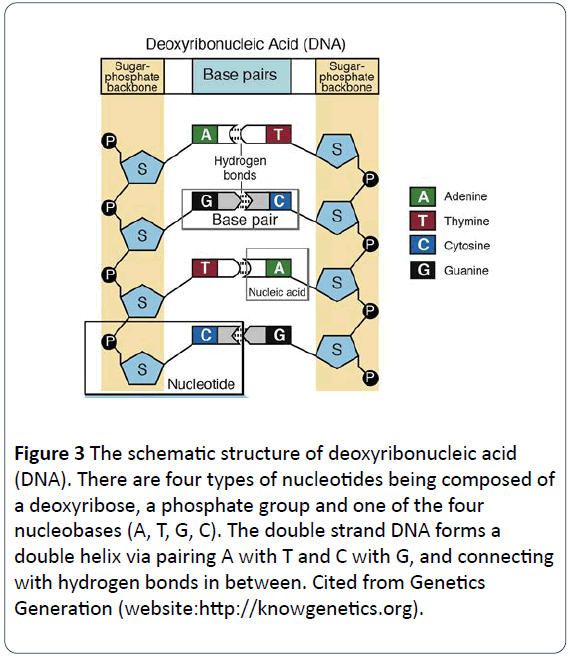
Figure 3: The schematic structure of deoxyribonucleic acid (DNA). There are four types of nucleotides being composed of a deoxyribose, a phosphate group and one of the four nucleobases (A, T, G, C). The double strand DNA forms a double helix via pairing A with T and C with G, and connecting with hydrogen bonds in between. Cited from Genetics Generation (website:https://knowgenetics.org).
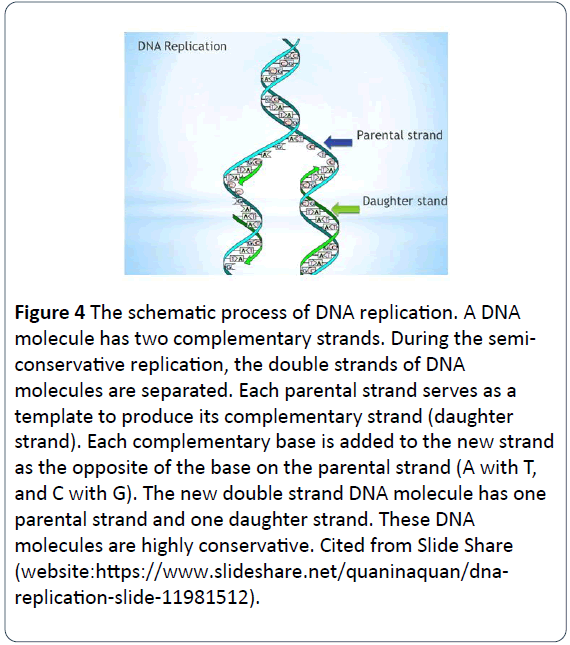
Figure 4: Schematický průběh replikace DNA. Molekula DNA má dvě komplementární vlákna. Během semikonzervativní replikace dochází k oddělení dvou vláken molekul DNA. Každé rodičovské vlákno slouží jako templát pro vytvoření svého komplementárního vlákna (dceřiného vlákna). Každá komplementární báze se přidává do nového vlákna jako opak báze na rodičovském vlákně (A s T a C s G). Nová dvouřetězcová molekula DNA má jedno rodičovské a jedno dceřiné vlákno. Tyto molekuly DNA jsou vysoce konzervativní. Citováno ze Slide Share (webová stránka:https://www.slideshare.net/quaninaquan/dnareplication- slide-11981512).
Proces spočívá v tom, že dvouřetězcová molekula DNA se odvíjí, přičemž každé ze dvou rodičovských vláken je odděleno a funguje jako rodičovská předloha pro syntézu nových dceřiných molekul DNA. Do dceřiného vlákna se přidávají komplementární nukleotidy, přičemž fosfáty a deoxyribosy tvoří páteř nových nukleotidů a nové báze se párují s opačnými bázemi na rodičovském vlákně pomocí pravidla párování bází (A se páruje s T a G s C) a drží na místě pomocí vodíkových vazeb . Nakonec má každá z nových dvouřetězcových molekul DNA jedno rodičovské a jedno dceřiné vlákno. Molekuly DNA se v tomto semikonzervativním modelu replikují, udržují genetické DNA konzervativní a konstantní a předávají se z jedné generace do druhé (Obrázek 5) .
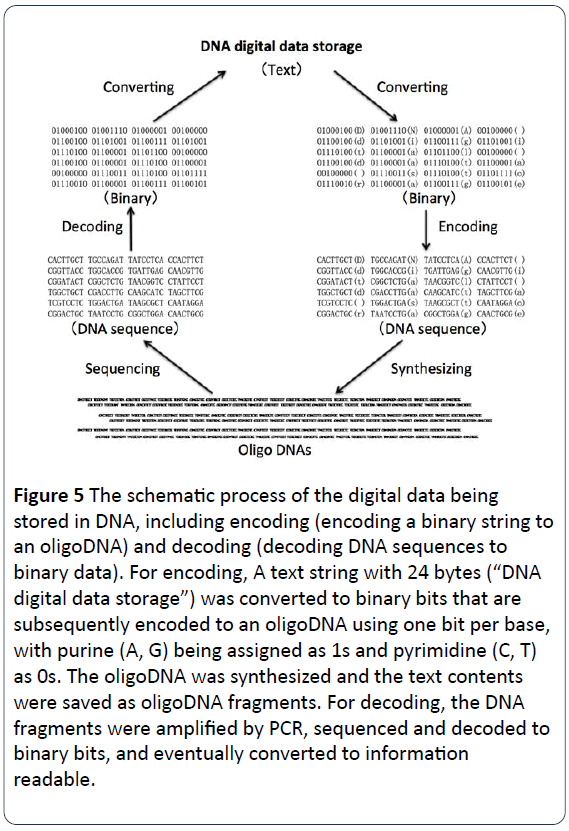
Obrázek 5: Schematický proces ukládání digitálních dat do DNA, včetně kódování (kódování binárního řetězce do oligoDNA) a dekódování (dekódování sekvencí DNA do binárních dat). Pro kódování: Textový řetězec o 24 bajtech („uložení digitálních dat v DNA“) byl převeden na binární bity, které jsou následně zakódovány do oligoDNA pomocí jednoho bitu na bázi, přičemž purinům (A, G) jsou přiřazeny jedničky a pyrimidinům (C, T) nuly. OligoDNA byla syntetizována a obsah textu byl uložen jako fragmenty oligoDNA. Pro dekódování byly fragmenty DNA amplifikovány pomocí PCR, sekvenovány a dekódovány na binární bity a nakonec převedeny na čitelnou informaci.
Proces ukládání digitálních dat DNA
Proces ukládání digitálních dat DNA spočívá v kódování a dekódování binárních dat do a ze syntetizovaných řetězců DNA. Texty, čísla, obrázky a další čitelné nebo viditelné údaje se nejprve převedou na binární jazyky s 0 a 1 místo 0 a pak se zakódují do sekvencí nukleotidů DNA se čtyřmi bázemi (A, C, G, T) místo 0 a 1 . Například velké písmeno „D“ je v binární soustavě „01000100“, malé písmeno „d“ je „01100100“ a prázdné “ “ je „00100000“ (obrázek 1). Na obrázcích 3 a 5 byla věta „DNA digital data storage“ převedena do binární verze, aby se získaly binární kódy o 24 bytech. Poté jsou binární kódy (binární bity) zakódovány do kódů DNA. Každá ze čtyř bází (A, C, G a T) by měla být přiřazena jako 1 nebo 0. Například purin (A, G) je přiřazen jako 1s, přičemž pyrimidin (C, T) je jako 0s. Nebo dvě báze G a T jsou přiřazeny jako 1s, přičemž zbylé dvě A a C jsou 0s. Jak je znázorněno na obrázku 4, pro kódování dat byl textový řetězec o 24 bajtech („digitální úložiště dat DNA“) převeden na binární bity, které jsou následně zakódovány do oligo DNA pomocí 1 bitu na bázi, přičemž purin (A, G) je přiřazen jako 1s a pyrimidin (C, T) jako 0s. Oligo DNA byla chemicky syntetizována a obsah textu byl poté uložen jako fragmenty oligo DNA pro dlouhodobé uložení. Pro dekódování dat byly fragmenty DNA amplifikovány pomocí PCR, sekvenovány a dekódovány na binární bity jednou denně, abychom mohli vyvést binární data, která mají být čitelná, musíme data načíst. Nakonec přečtení dat z knihovny sekvencí DNA spočívá v sekvenování jedinečných molekul DNA, převedení sekvenčních informací do původních digitálních dat podle potřeby nebo požadavku (obrázek 5) .
Výhody média pro ukládání dat DNA
Jak bylo uvedeno výše, globálních dat prudce přibývá exponenciální rychlostí. Tradiční média se nemohou dostatečně vypořádat s požadavkem na ukládání velkého množství dat . DNA může sloužit jako možné médium pro ukládání digitálních dat díky svým potenciálním výhodám, jako je vysoká hustota, vysoká účinnost replikace, dlouhodobá trvanlivost a dlouhodobá stabilita (https:// www.scientificworldinfo.com) . DNA při své teoretické maximální kapacitě může zakódovat přibližně dva bity na jeden nukleotid . Celé datové centrum postavené společností IBM v roce 2011 má kapacitu pro ukládání dat přibližně 100 petabajtů (PB). Vzhledem k tomu, že má vysokou hustotu, může však DNA působící jako médium pro ukládání dat uchovávat velké množství dat při malé velikosti. Jediný gram DNA může při svém teoretickém maximu uložit přibližně 200 PB dat, což je téměř dvakrát více než celé datové centrum IBM . Jinými slovy, všechny informace zaznamenané na celém světě mohou být uloženy v několika kilogramech DNA, nebo se rovnají pouze jedné krabici od bot ve srovnání s požadavkem milionů velkých datových úložných center pro tradiční média .
Datové médium DNA je schopné dlouhodobého ukládání díky tomu, že má vysokou trvanlivost . DNA může vydržet tisíce let v chladných, suchých a tmavých místech. Dokonce i v horším prostředí je poločas rozpadu DNA až sto let . DNA si může uchovat stabilitu při nízkých nebo vysokých teplotách v širokém rozmezí od -800 °C do 800 °C . Nosiče DNA mohou také zabezpečit data více než tradiční digitální nosiče dat . Přestože nových dat přibývá exponenciální rychlostí, většina z nich je uložena v archivech pro dlouhodobé skladování . Tato chladná data nebudou okamžitě vyhledána nebo často používána. Jejich ukládání na média DNA je tedy jednoduché, pohodlné a finančně nenáročné. Další výhodou je, že DNA je vysoce konzervovaná. Přírodní DNA se mohou přesně replikovat s vysokou účinností a vždy s pravidlem párování bází (A s T, C s G) (obrázek 3) . Médium DNA tak může vysoce zachovat věrnost dat po dlouhou dobu.
Výzvy pro médium pro ukládání dat DNA
Na základě svých jedinečných vlastností a ve srovnání s tradičními médii by DNA mohla být potenciálním a slibným médiem pro ukládání digitálních dat . Než však bude možné DNA komerčně využít, čeká ji ještě dlouhá cesta. Problémy, se kterými se musíme vypořádat, existují v různých aspektech, včetně vysoké ceny, nízké propustnosti, omezeného přístupu k datovému úložišti, krátkých syntetických oligo fragmentů DNA, chybovosti při syntéze a sekvenování .
Použití DNA při ukládání dat je mnohem dražší než ostatní tradiční média, jako jsou pásky, disky a HDD (pevné disky) (https://www.scientificworldinfo.com) . V současné době stojí zakódování a dekódování dat téměř 15 000 USD za megabajt (MB). Současná technologie syntézy DNA je přitom omezená a lze syntetizovat pouze krátké oligo sekvence DNA. Maximální délka každého oligo fragmentu DNA je omezena na několik set nukleotidů . K uložení jednoho archivního souboru, zejména 1 velkého souboru, tak mohou být zapotřebí stovky tisíc oligo DNA. A také je časově náročné data zapsat do oligo DNA a načíst je z nich, přičemž se na tom podílí více kroků včetně převodu dat do binární podoby, kódování binární podoby do oligo DNA, syntézy a ukládání sekvencí DNA a načítání jedinečných sekvencí z knihovny pro ukládání DNA, sekvenování a dekódování a nakonec převod binární podoby na čitelná data. Tradiční média, jako jsou disk a páska, mají své logické adresní informace, oligo DNA je však nemají. Je tedy velmi obtížné adresovat jedinečnou zakódovanou sekvenci DNA, kterou očekáváme, že bude mít . Mezitím je důležitý náhodný přístup k ukládání dat na bázi DNA, oligo DNA však nemají schopnost náhodného přístupu . Prostřednictvím současných přístupů je pro ukládání dat DNA k dispozici pouze hromadný přístup. Celé datové úložiště na bázi DNA musí být tříděno, sekvenováno a dekódováno z datového úložiště DNA, přestože potřebujeme přečíst pouze jeden bajt . Proto je zapotřebí správný primer používaný k selektivnímu načtení správné sekvence DNA. To také zajistí náhodný přístup během sekvenování DNA a načítání dat. Sekvenování pomocí jedinečného primeru může selektivně přečíst pouze požadovanou oligoDNA, nikoli celou knihovnu DNA . A v současné době nejsou syntéza a sekvenování DNA zcela dokonalé. Během syntézy a sekvenování DNA může dojít k výskytu inzerce, delece, substituce a dalších chyb, přičemž chybovost je přibližně 1 % na nukleotid . Technologie a náklady na syntézu a sekvenování DNA nejsou vhodné pro současné ukládání dat .
Předpoklad pro médium pro ukládání dat DNA
Vzhledem k exponenciálnímu nárůstu globálních dat, nedostatku dostatečných úložných prostor a požadavku na inovativní přístupy k ukládání se DNA jako potenciální zcela nové médium stává horkým tématem v oblasti ukládání velkých dat. Díky vysoké hustotě, vysoké účinnosti replikace, dlouhodobé trvanlivosti a stabilitě vykazuje DNA oproti tradičním médiím pro ukládání dat své vlastní výhody . Zatím jsou aplikace digitálního ukládání dat pomocí DNA omezené kvůli vysokým nákladům, nedostatečné schopnosti náhodného přístupu, časové náročnosti při kódování a dekódování dat. Naštěstí pokrok v oblasti technologie DNA jde rychle kupředu. Například na dokončení sekvenování prvního lidského genomu spolupracovali a pracovali světoví vědci přibližně 10-20 let, přičemž celkové náklady v roce 2013 činily 3 miliardy dolarů (webové stránky Human Genome Project (HGP): https://www.genome.gov/human-genomeproject).
Závěr
V dnešní době vědcům stačí několik tisíc dolarů a pár týdnů k dokončení sekvenace jednoho celého lidského genomu. A očekává se, že v blízké budoucnosti bude sekvenování jednoho lidského genomu stát jen sto dolarů nebo méně než několik hodin. Lze tedy očekávat, že náklady budou dostupné. Pro náhodný přístup k informacím a jejich adresování vyřešili vědci tento problém návrhem jedinečných primerů, které selektivně adresují a získávají požadované informace. Aby se zabránilo výskytu chyb, jsou metadata pro opravu chyb zakódována v oligo fragmentech DNA. Mezitím byly vynalezeny jednomolekulární sekvenátory DNA, které jsou v současné době k dispozici. Jsou praktické a přenosné. Mohou dále snížit náklady na sekvenování DNA a zjednodušit vyhledávání informací o DNA. V návaznosti na pokrok v technologiích ukládání dat DNA tak bude DNA sloužící jako médium pro ukládání dat zlatou příležitostí v této éře velkých dat.
- Mayer C, McInroy GR, Murat P, Delft PV, Balasubramanian S (2016) An epigenetics-inspired DNA-based data storage system. Angew Chem Int Ed Engl 55: 11144-11148.
- Swati A, Mathuria, F, Bhavani, S, Malathy E, Mahadevan R (2017) A review on various encoding schemes used in digital DNA data storage. Int J Civil Eng Technol 8: 7-10.
- Appuswamy RLK, Barbry P, Antonini M, Madderson O, Freemont P (2019) Archive: Použití DNA v hierarchii úložišť DBMS. CIDR 2019, Biennal Conference on Innovative Data Systems Research, Kalifornie, USA.
- De Silva PY, GU Ganegoda (2016) New trends of digital data storage in DNA. Biomed Res Int pp: 8072463-8072472.
- Panda DM, Baig KA, Swain MJ, Behera A, Dash D (2018) DNA as a digital information storage device: hope or hype? Biotech 8: 9-15.
- Chen K, Kong J, Zhu J, Ermann N, Predki P a další (2019) Digital data storage using DNA nanostructures and solid-state Nanopores. Nano Lett 19: 1210-1215.
- Yazdi S, Gabrys R, Milenkovic O (2017) Portable and error-free DNA-based data storage. Sci Rep 7: 5011-5013.
- Church GM, Gao Y, Kosuri S (2012) Next-generation digital information storage in DNA. Science 337: 1628-1630.
- Kuang SY, Zhu G, Wang ZL (2018) Triboelectrification-Enabled Self-Powered Data Storage. Adv Sci (Weinh) 5: 1700658.
- Block FE (1987) Analog and digital computer theory. Int J Clin Monit Comput 4: 47-51.
- O‘ Driscoll A, Sleator RD (2013) Synthetic DNA: the next generation of big data storage. Bioengineered 4: 123-1235.
- Portin P (2014) Zrod a vývoj teorie dědičnosti DNA: šedesát let od objevu struktury DNA. J Genet 93: 293-302.
- Leu K, Obermayer B, Rajamani S, Gerland U, Chen IA (2011) The prebiotic evolutionary advantage of transfering genetic information from RNA to DNA. Nucleic Acids Res 39: 8135-8147.
- Burgers PMJ, Kunkel TA (2017) Eukaryotic DNA replication Fork. Annu Rev Biochem 86: 417-438.
- Akram F, Haq I, Ali H, Laghari AT (2018) Trends to store digital data in DNA: an overview. Mol Biol Rep 45: 1479-1490.
- Organick L, Ang SD, Chen YJ, Lopez R, Yekhanin S a další (2018) Random access in large-scale DNA data storage. Nat Biotechnol 36: 242-248.
- Bornholt J, Lopez R, Carmean DM, Ceze L, Seelig G, et al. (2016) A DNA-based archival storage system. ASPLOS 201 (21st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Atlanta, GA).
- Newman S, Stephenson AP, Willsey M, Nguyen BH, Takahashi CN, et al. (2019) High density DNA data storage library via dehydration with digital microfluidic retrieval. Nat Commun 10: 1706-1710.
- Yazdi SM, Yuan Y, Ma J, Zhao H, Milenkovic O (2015) A rewritable, random-access DNA-based storage system. Sci Rep 5: 14138-14140.
- Ahn T, Ban H, Park H (2018) Ukládání digitální informace v DNA s dlouhým čtením. Genomics Inform 16: e30-35.
- Bayley H (2017) Single-molecule DNA sequencing: Getting to the bottom of the well. Nat Nanotechnol 12: 1116-1117.