Jurnal de științe medicale
Locuri cheie
Stocarea digitală a datelor; Acid dezoxiribonucleic (ADN); Binar; Codificare; Decodare; Secvențiere
Introducere
În zilele noastre, este o eră explozivă a datelor mari. Aceste date mari există și acoperă aproape peste tot, de la magazinele alimentare la bănci, de la offline la online, de la academie la industrie, de la spital la comunitate, de la organizație la guvern. Stocarea și gestionarea datelor mari devine o preocupare serioasă. În prezent, majoritatea datelor din întreaga lume sunt stocate în principal pe suporturi magnetice și optice, cum ar fi HDD (hard disk drive), DISK-uri, CD-uri, casete, DVD-uri, hard disk-uri portabile și unități USB . Cu toate acestea, viteza de creștere a acestor date de arhivare crește în mod exploziv la o rată exponențială. Aceste suporturi tradiționale și capacitatea lor limitată de stocare a datelor nu pot satisface cerința de creștere rapidă a datelor digitale. Între timp, durabilitatea de stocare a datelor pe aceste suporturi reprezintă o provocare majoră. Durabilitatea lor este foarte limitată. Aceste suporturi durează doar o perioadă foarte limitată de timp . De exemplu, discurile pot dura câțiva ani, iar benzile durează câteva decenii. Alte tipuri de stocare electronică pot fi păstrate în condiții bune timp de câteva decenii. Capacitatea de stocare a datelor este o altă problemă pentru stocarea datelor digitale mari. Un CD poate stoca câteva sute de megabytes (MB) de date. Un hard disk mare poate stoca câțiva terabytes (TB) de date. Cu toate acestea, capacitatea lor este departe de cerința datelor informaționale explozive .
După cum a spus Patrizio, există în total 33 de Zettabytes (ZBs) de date la nivel mondial în 2018 (https://www.networkworld.com), echivalentul a 22 trilioane de gigabytes (GBs). Prin urmare, sunt necesare o tehnologie de stocare nouă și un sistem inovator pentru a răspunde cerințelor acestei epoci moderne. Se așteaptă ca acidul dezoxiribonucleic (ADN), datorită avantajelor sale unice, să fie un mediu ideal pentru stocarea datelor digitale . Stocarea datelor digitale în ADN nu este o poveste nouă. De fapt, aceasta a fost descrisă de fizicianul sovietic Mihail Neiman în anii ’60 (https:// www.geneticsdigest.com). Cu toate acestea, a fost prima dată când s-a demonstrat că ADN-ul poate stoca date digitale în 1988 . Aici, vom prezenta în primul rând aplicațiile ADN-ului ca un nou mediu de stocare a datelor digitale și vom discuta în continuare mai multe detalii în acest domeniu în care ADN-ul servește ca mediu de stocare a datelor.
Revizuirea studiilor anterioare
Sistemul numeric binar
Computerele și alte dispozitive electronice digitale stochează date și funcționează cu sistemul numeric binar care utilizează doar două numere digitale sau 0 și 1 . Textele sunt convertite în versiunea binară în sistemul informatic. La rândul lor, calculatoarele operează și calculează în binar, în cele din urmă convertesc informațiile în texte lizibile. Un octet conține opt biți care constau fie din 0, fie din 1 și au 28 (256) valori posibile (de la 0 la 255) și stochează o singură literă (figura 1 și tabelul 1) . După cum se arată în tabelul de conversie ASCII (tabelul 1). Cele douăzeci și șase de litere cu majuscule și minuscule sunt convertite între litera, binar și hexazecimal. Pentru a stoca un fișier sau un document mare este nevoie de mult mai multe date de memorie. Un cântec obișnuit poate avea nevoie de zeci de megabytes, cu câțiva gigabytes pentru a stoca un film și mai mulți terabytes pentru cărțile stocate într-o bibliotecă mare. După cum se arată în tabelul 2 sunt dimensiunile de măsură și de memorie pentru utilizarea sistemului binar, de la cea mai mică unitate „byte” până la unitățile mari, inclusiv byte (B), kilobyte (KB), megabyte (MB), gigabyte (GB), terabyte (TB), pegabyte (PB), Exabyte (EB), zettabyte (ZB), yottabyte (YB), brontobyte (BB), Geopbyte (GPB) și așa mai departe (https://www.geeksforgeeks.org&https://whatsabyte.com). Unitățile precum brontobyte (BB), Geopbyte (GPB) sunt valori uriașe inimaginabile care s-ar putea să nu fie folosite niciodată în lumea noastră reală (Tabelul 2).

Figura 1: Șirul de text „DNA digital data storage” a fost convertit ca biți binari.
Table 1: The conversion ASCII table of the twenty-six letters with the upper and lower cases among letter, binary and hexadecimal.
| Letter | Binary | Hexadecimal | Letter | Binary | Hexadecimal |
|---|---|---|---|---|---|
| A | 1000001 | 41 | a | 1100001 | 61 |
| B | 1000010 | 42 | b | 1100010 | 62 |
| C | 1000011 | 43 | c | 1100011 | 63 |
| D | 1000100 | 44 | d | 1100100 | 64 |
| E | 1000101 | 45 | e | 1100101 | 65 |
| F | 1000110 | 46 | f | 1100110 | 66 |
| G | 1000111 | 47 | g | 1100111 | 67 |
| H | 1001000 | 48 | h | 1101000 | 68 |
| I | 1001001 | 49 | i | 1101001 | 69 |
| J | 1001010 | 4A | j | 1101010 | 6A |
| K | 1001011 | 4B | k | 1101011 | 6B |
| L | 1001100 | 4C | l | 1101100 | 6C |
| M | 1001101 | 4D | m | 1101101 | 6D |
| N | 1001110 | 4E | n | 1101110 | 6E |
| O | 1001111 | 4F | o | 1101111 | 6F |
| P | 1010000 | 50 | p | 1110000 | 70 |
| Q | 1010001 | 51 | q | 1110001 | 71 |
| R | 1010010 | 52 | r | 1110010 | 72 |
| S | 1010011 | 53 | s | 1110011 | 73 |
| T | 1010100 | 54 | t | 1110100 | 74 |
| U | 1010101 | 55 | u | 1110101 | 75 |
| V | 1010110 | 56 | v | 1110110 | 76 |
| W | 1010111 | 57 | w | 1110111 | 77 |
| X | 1011000 | 58 | x | 1111000 | 78 |
| Y | 1011001 | 59 | y | 1111001 | 79 |
| Z | 1011010 | 5A | z | 1111010 | 7A |
*Note: ACSII (American Standard Code for Information Interchange): serial digital codes to represent number, letters, numerals, and other symbols and to be used as a standard format in the computer system.
Table 2: The sizes of measurement and memory.
| Sizes | Byte Magnitude | Units | Storage* |
|---|---|---|---|
| 1 B | 100 | Byte | A character „A”, „1”, „$” |
| 10 B | 101 | ||
| 100 B | 102 | ||
| 1 KB | 103 | Kilo byte | The size for graphics of small websites ranges between 5 and 100 KB |
| 10 KB | 104 | ||
| 100 KB | 105 | ||
| 1 MB | 106 | Mega byte ( 1 MB: 1 million) |
The size for a high resolution JPEG image is about 1-5 MB |
| 10 MB | 107 | The size for a 3-minute song is about 30 MB | |
| 100 MB | 108 | ||
| 1 GB | 109 | Giga byte | The size for a standard DVD drive is about 5 GB |
| 10 GB | 1010 | (1 GB: 1 billion) | |
| 100 GB | 1011 | ||
| 1 TB | 1012 | Tera byte (1 TB: 1 trillion) |
The size for a typical internal HDD is about 2 TB |
| 10 TB | 1013 | ||
| 100 TB | 1014 | ||
| 1 PB | 1015 | Peta byte (1 PB: 1 quadrillion) |
Google store over 100 PB of all data in their drivers. |
| 10 PB | 1016 | ||
| 100 PB | 1017 | ||
| 1 EB | 1018 | Exa byte (1 EB: 1 quintillion) |
Several hundred EBs of data are transferred over global internet per year Facebook built an entire data center to store 1 EB of data in 2013 |
| 10 EB | 1019 | ||
| 100 EB | 1020 | ||
| 1 ZB | 1021 | Zetta byte (1 ZB: 1 sextillion) |
33 ZBs of global data in 2018. 160-180 ZBs of data is predicted in 2025. |
| 10 ZB | 1022 | ||
| 100 ZB | 1023 | ||
| 1 YB | 1024 | Yotta byte (1 YB: 1 septillion) |
1YB = 1 million EBs 1 YB = Size of the entire World Wide Web |
| 10 YB | 1025 | ||
| 100 YB | 1026 | ||
| 1 BB | 1027 | Bronto byte (1 BB: 1 octillion) |
1BB equals to 1 million ZBs The only thing there is to say about a Brontobyte is that it is a 1 followed by 27 zeros! |
| 10 BB | 1028 | ||
| 100 BB | 1029 | ||
| 1 GPB | 1030 | Geop byte (1 GPB: 1 nonillion) | 1, No one knows why this term was created. It is highly doubtful that anyone alive today will EVER see a Geopbyte hard drive. |
The digital data storage
Digital Data Storage (DDS) was introduced and developed in 1980s. It is a computer-based data storage technology that is based on the Digital Audio Tape (DAT) format. These digital data were stored on the silicon-based chips. Silicon is the primary material of most semiconductor and microelectronic chips. Siliciul pur de tip memorie este rar întâlnit în natură. Se preconizează că tot siliciul de calitate pentru microcipuri din întreaga lume se va epuiza în viitorul apropiat. De asemenea, Legea lui Moore (Numărul de tranzistori găzduiți pe circuitele integrate aproape că se dublează la fiecare doi ani, sau cipurile cu mai mulți tranzistori funcționează mai repede cu mai mulți tranzistori) se apropie de sfârșit . Astfel, cipurile nu pot găzdui tranzistori suplimentari și vor ajunge la limita capacității lor.
Între timp, majoritatea datelor digitale actuale sunt stocate în mediile tradiționale magnetice, optice și altele, cum ar fi HDD (hard disk drive) și CD-uri. Pe lângă capacitatea lor limitată de stocare a datelor, aceste suporturi pot fi păstrate și pentru un timp foarte limitat . Ele sunt sensibile la mediul înconjurător sau la condițiile de salvare a datelor. Orice modificare a mediului și a condițiilor, cum ar fi expunerea magnetică, umiditatea ridicată, temperatura ridicată, deteriorarea mecanică, poate duce, eventual, la deteriorarea acestor suporturi sau la pierderea datelor. Iar utilizarea frecventă poate duce, de asemenea, la deteriorarea lor sau la pierderea de date. De asemenea, pentru a stoca o cantitate mare de date și pentru a satisface cerința de creștere explozivă a datelor, avem nevoie de o cantitate mare de suporturi precum discuri, CD-uri, DVP-uri, hard disk-uri . Acestea vor duce la costuri ridicate și vor necesita mult timp.
Simultan, creșterea numărului de date digitale și cerința de stocare a datelor cresc într-un ritm exponențial. IBM a construit un centru mare cu o capacitate de stocare a datelor de 120 PBs în 2011. Facebook a construit un alt centru mai mare cu o capacitate de stocare a 1 EB (1000 PBs) de date în 2013. Toți utilizatorii digitali din întreaga lume au produs peste 44 exabytes (EBs) (44000 PBs) de date pe zi. Au fost în total 1 zettabyte (ZB, 1000EBs sau 1 milion de PBs) de date produse la nivel global în 2010 și 33 de zettabytes (ZB) de date în 2018, cu 150-200 de zettabytes (ZBs) fiind prezise în 2025 (citat de pe site-ul Datanami: https:// www.datanami.com și de pe site-ul Network world: https:// www.networkworld.com) . Pentru a stoca aceste date ar fi nevoie de sute de mii de centre spațiale uriașe. În 2018, Facebook a avut în total 15 locații de centre de date în 2018, fiind anunțate mai multe centre noi. Aceștia vor construi patru centre de date suplimentare în Nebraska, constând în șase clădiri mari, cu un spațiu de stocare a datelor de peste 2,6 milioane de metri pătrați. În fine, spațiul de datastoring nu poate prinde niciodată creșterea exponențială a datelor. De asemenea, mediile de stocare actuale nu pot satisface cerințele de stocare. Există o nevoie urgentă de a dezvolta o nouă generație de tehnologie de stocare a datelor, în locul actualei tehnologii de stocare a datelor pe bază de siliciu. Datorită caracteristicilor sale unice și a avantajelor sale potențiale, acidul dezoxiribonucleic (ADN), ca posibil suport de stocare a datelor digitale, se apropie de stadiul central al stocării datelor.
Informațiile de bază ale acidului dezoxiribonucleic (ADN)
În 1953, Dr. Crick și Watson au dezvăluit că o moleculă de ADN are șiruri duble care se înfășoară unul în jurul celuilalt și formează o structură dublu elicoidală . În general, materialele genetice din majoritatea organismelor naturale sunt șuvițe duble de ADN elicoidale, unele dintre ele fiind șuvițe simple de ADN, iar altele fiind șuvițe simple sau duble de ARN. Componentele ADN sau nucleotidele sunt formate din baze azotate, grupe fosfat și grupe dezoxiriboză. Cele două litere sunt structurate ca și coloana vertebrală a fiecărei molecule de ADN, fiecare pereche de baze din fiecare catenă urmând să se conecteze printr-o legătură de hidrogen. Nucleotidele ADN sunt alcătuite din patru tipuri de baze, inclusiv adenină (A), citozină (C), guanină (G) și timină (T) (figura 2) , acidul ribonucleic (ARN) având patru tipuri de baze, inclusiv adenină (A), citozină (C), guanină (G) și uracil (U) în loc de timină (T). Adenina (A) și guanina (G) sunt purine, iar citosina (C), timina (T) și uracilul (U) sunt pirimidine . In DNA molecules, the base-pairing rule is that A pairs with T, and G pairs with C (Figures 3 and 4) .
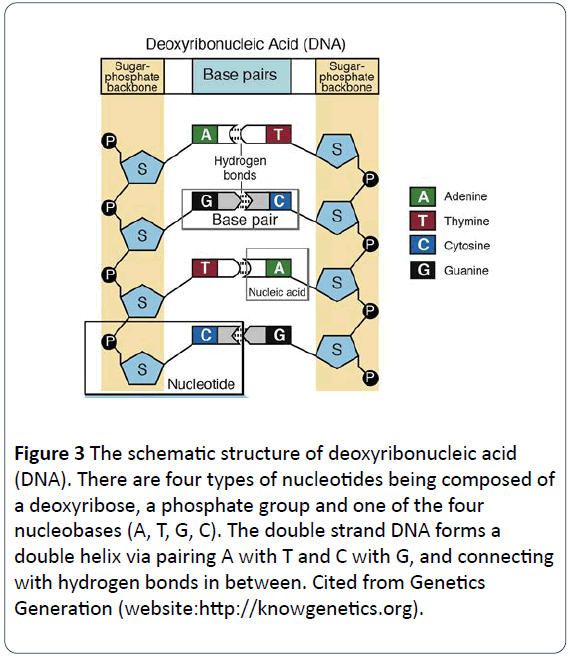
Figure 3: The schematic structure of deoxyribonucleic acid (DNA). There are four types of nucleotides being composed of a deoxyribose, a phosphate group and one of the four nucleobases (A, T, G, C). The double strand DNA forms a double helix via pairing A with T and C with G, and connecting with hydrogen bonds in between. Cited from Genetics Generation (website:https://knowgenetics.org).
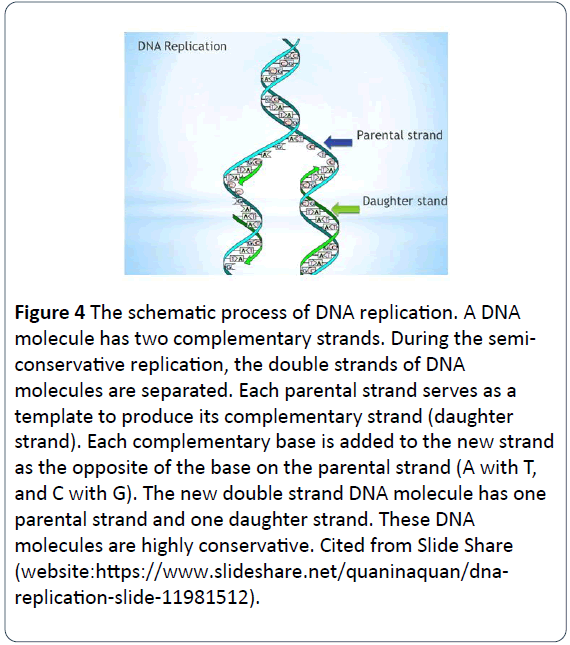
Figure 4: Procesul schematic de replicare a ADN-ului. O moleculă de ADN are două catene complementare. În timpul replicării semiconservative, șirurile duble ale moleculelor de ADN sunt separate. Fiecare șuviță parentală servește drept șablon pentru a produce șuvița sa complementară (șuvița fiică). Fiecare bază complementară este adăugată la noul șir ca fiind opusă bazei de pe șirul parental (A cu T și C cu G). Noua moleculă de ADN dublu catenar are o catenă parentală și o catenă fiică. Aceste molecule de ADN sunt foarte conservatoare. Citat din Slide Share (website:- slide-11981512).
Procesul constă în faptul că o moleculă de ADN dublu catenar se derulează, fiecare dintre cele două catene parentale fiind separată și acționează ca un șablon parental pentru sinteza unor noi molecule de ADN fiice. Nucleotidele complementare sunt adăugate la catena fiică, cu fosfați și deoxiriboze pentru a forma coloana vertebrală a noilor nucleotide și baze noi pentru a se împerechea cu opusul bazelor de pe catena parentală prin regula de împerechere a bazelor (A se împerechează cu T, iar G se împerechează cu C) și pentru a se menține în poziție cu legături de hidrogen . În cele din urmă, fiecare dintre noile molecule de ADN dublu catenar are un catenar parental și un catenar fiică. Moleculele de ADN se replică în acest model semi-conservativ, mențin ADN-urile genetice conservatoare și constante și trec de la o generație la alta (figura 5) .
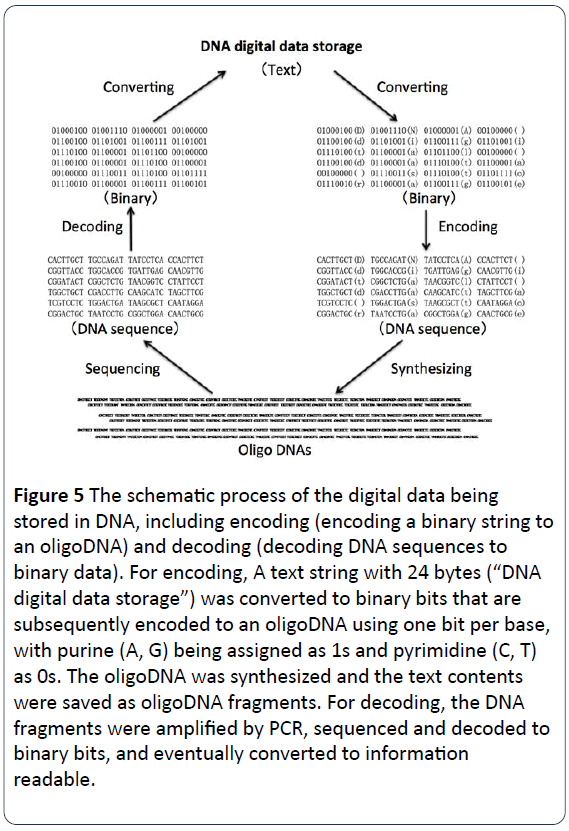
Figura 5: Procesul schematic de stocare a datelor digitale în ADN, inclusiv codificarea (codificarea unui șir binar într-un oligoADN) și decodificarea (decodificarea secvențelor de ADN în date binare). Pentru codificare, Un șir de text cu 24 de octeți („stocare de date digitale în ADN”) a fost convertit în biți binari care sunt ulterior codificați într-un oligoADN utilizând câte un bit pe bază, purina (A, G) fiind atribuită ca 1s și pirimidina (C, T) ca 0s. OligoADN-ul a fost sintetizat, iar conținutul textului a fost salvat ca fragmente de oligoADN. Pentru decodare, fragmentele de ADN au fost amplificate prin PCR, secvențiate și decodate în biți binari și, în cele din urmă, convertite în informații lizibile.
Procesul de stocare a datelor digitale ADN
Procesul de stocare a datelor digitale ADN constă în codificarea și decodificarea datelor binare în și din șiruri de ADN sintetizate. Textele, numerele, imaginile și altele care pot fi citite sau vizibile sunt convertite mai întâi în limbaje binare cu 0 și 1 în loc de 0 și 1, iar apoi sunt codificate în secvențe de nucleotide ADN, cu cele patru baze (A, C, G, T) în loc de 0 și 1 . De exemplu, o literă majusculă „D” este „01000100” în binar, o literă minusculă „d” este „01100100” cu un spațiu gol ” ” este „00100000” (figura 1). În figurile 3 și 5, propoziția „stocarea digitală a datelor ADN” a fost convertită în versiunea binară pentru a obține coduri binare cu 24 de octeți. Apoi, codurile binare (biți binari) sunt codificate în coduri ADN. Fiecare dintre cele patru baze (A, C, G și T) ar trebui să fie atribuită ca 1 sau 0. De exemplu, purina (A, G) este atribuită ca 1s, iar pirimidina (C, T) ca 0s. Sau, cele două baze G și T sunt atribuite ca 1s, celelalte două baze A și C fiind 0s. După cum se arată în figura 4, pentru codificarea datelor, un șir de text cu 24 de octeți („stocare digitală de date ADN”) a fost convertit în biți binari care sunt ulterior codificați într-un oligo ADN folosind 1 bit pe bază, purina (A, G) fiind atribuită ca 1s, iar pirimidina (C, T) ca 0s. Oligo ADN-ul a fost sintetizat chimic, iar conținutul textului a fost apoi salvat ca fragmente de oligo ADN pentru stocarea pe termen lung. Pentru decodarea datelor, fragmentele de ADN au fost amplificate prin PCR, secvențiate și decodate în biți binari o dată pe zi, trebuie să recuperăm datele pentru a scoate date binare care să poată fi citite. În cele din urmă, citirea datelor din biblioteca de secvențe de ADN constă în secvențierea moleculelor unice de ADN, convertirea informațiilor de secvențiere în datele digitale originale, după cum este necesar sau necesar (figura 5) .
Avantajele suportului de stocare a datelor ADN
După cum s-a menționat mai sus, datele globale sunt în creștere bruscă la o rată exponențială. Mediile tradiționale nu pot face față în mod suficient cerinței de stocare a datelor de mari dimensiuni . ADN-ul poate servi ca un posibil mediu de stocare a datelor digitale, cu avantajele sale potențiale, cum ar fi densitatea mare, eficiența ridicată a replicării, durabilitatea și stabilitatea pe termen lung (https:// www.scientificworldinfo.com) . ADN-ul, la capacitatea sa maximă teoretică, poate codifica aproximativ doi biți pe nucleotidă . Un întreg centru de date construit de IBM în 2011 are o capacitate de stocare a datelor de aproximativ 100 petabytes (PB). Cu toate acestea, datorită faptului că are o densitate ridicată, ADN-ul, acționând ca mediu de stocare a datelor, poate stoca o cantitate mare de date la o dimensiune mică. Un singur gram de ADN, la maximul său teoretic, poate stoca aproximativ 200 PBs de date, de aproape două ori mai mult decât întregul centru de date IBM . Cu alte cuvinte, toate informațiile înregistrate în întreaga lume pot fi stocate în câteva kilograme de ADN, sau echivalentul unei singure cutii de pantofi, în comparație cu necesarul de milioane de centre mari de stocare a datelor pentru mediile tradiționale .
Mediul ADN codificat cu date este capabil de stocare pe termen lung datorită faptului că are o durabilitate ridicată . ADN-ul poate rezista timp de mii de ani în locuri reci, uscate și întunecate. Chiar și în condiții de mediu mai rău, timpul de înjumătățire al ADN-ului este de până la o sută de ani . ADN-ul se poate păstra stabil la temperaturi scăzute sau ridicate, cu o gamă largă de temperaturi cuprinse între -800°C și 800°C . Suportul ADN poate, de asemenea, securiza datele mai mult decât suporturile de date digitale tradiționale . Deși noile date cresc cu o rată exponențială, cele mai multe dintre ele sunt salvate în arhive pentru stocarea pe termen lung . Aceste date reci nu vor fi recuperate imediat sau utilizate frecvent. Astfel, stocarea lor în medii ADN este simplă, convenabilă și fără costuri. Un alt avantaj este faptul că ADN-ul este foarte bine conservat. ADN-urile naturale se pot replica cu precizie la o eficiență ridicată și întotdeauna cu regula de împerechere a bazelor (A cu T, C cu G) (figura 3) . Astfel, suportul ADN poate păstra foarte bine fidelitatea datelor pentru o perioadă lungă de timp.
Provocările pentru suportul de stocare a datelor ADN
Pe baza caracteristicilor sale unice și în comparație cu suporturile tradiționale, ADN-ul ar putea fi suportul potențial și promițător pentru stocarea datelor digitale . Cu toate acestea, mai este încă un drum lung de parcurs până când ADN-ul ar putea fi aplicat comercial. Provocările cu care trebuie să ne confruntăm există în diverse aspecte, inclusiv costul ridicat, randamentul scăzut, accesul limitat la stocarea datelor, fragmente sintetice scurte de oligo ADN, rata de eroare în sinteză și secvențiere .
Utilizarea ADN-ului în stocarea datelor este mult mai scumpă decât alte medii tradiționale, cum ar fi banda, discul și HDD (hard disk drive) (https://www.scientificworldinfo.com) . În prezent, codificarea și decodificarea datelor costă aproape 15.000 de dolari pe megabyte (MB). Între timp, tehnologia actuală de sinteză a ADN-ului este limitată, putând fi sintetizate doar secvențe scurte de oligo ADN. Lungimea maximă a fiecărui fragment de oligo ADN este limitată la câteva sute de nucleotide . Astfel, pentru a stoca un singur fișier arhivat, în special 1 fișier mare poate avea nevoie de sute de mii de oligo ADN-uri. Și, de asemenea, este consumator de timp pentru scrierea datelor în oligo ADN-uri și recuperarea acestora, cu implicarea mai multor etape, inclusiv conversia datelor în binar, codificarea binarului în oligo ADN, sintetizarea și stocarea secvențelor de ADN și recuperarea secvențelor unice din biblioteca de stocare a ADN-ului, secvențierea și decodificarea și, în cele din urmă, conversia binarului în date lizibile. Suporturile tradiționale, cum ar fi discul și banda, au informațiile lor de adresare logică, însă oligoADN-urile nu au. Astfel, este foarte dificil de adresat secvența unică de ADN codificată pe care ne așteptăm să o avem . Între timp, accesul aleatoriu la stocarea datelor pe bază de ADN este important, cu toate acestea, oligo ADN-urile nu au capacitatea de acces aleatoriu . Prin intermediul abordărilor actuale, pentru stocarea datelor ADN este disponibil doar accesul în masă. Întreaga stocare de date pe bază de ADN trebuie să fie sortată, secvențiată și decodificată din stocarea de date ADN, chiar dacă avem nevoie doar să citim un singur octet . Prin urmare, este necesar primerul potrivit utilizat pentru a prelua selectiv secvența corectă de ADN. Acest lucru va asigura, de asemenea, un acces aleatoriu în timpul secvențierii ADN și al recuperării datelor. Secvențierea cu amorsă unică poate citi selectiv doar oligoADN-ul necesar, mai degrabă decât întreaga bibliotecă de ADN . Și în prezent, sinteza și secvențierea ADN nu sunt complet perfecte. În timpul sintezei și secvențierii ADN, pot apărea erori de inserție, deleție, substituție și alte erori, rata de eroare fiind de aproximativ 1% pe nucleotidă . Tehnologia și costul sintezei și secvențierii ADN nu sunt adecvate pentru stocarea actuală a datelor .
Respectiv pentru mediul de stocare a datelor ADN
Datorită creșterii exponențiale a datelor globale, lipsei de spații de stocare suficiente și cerinței de abordări inovatoare de stocare, ADN-ul ca potențial mediu nou-nouț devine un subiect fierbinte în domeniul stocării datelor mari. Datorită densității ridicate, eficienței ridicate de replicare, durabilității și stabilității pe termen lung, ADN-ul prezintă avantaje proprii față de mediile tradiționale de stocare a datelor . Între timp, aplicațiile de stocare a datelor digitale pe bază de ADN au fost limitate din cauza costului ridicat, a lipsei capacității de acces aleatoriu, a timpului consumat în codificarea și decodificarea datelor. Din fericire, progresul în domeniul tehnologiei ADN avansează rapid. De exemplu, pentru a finaliza secvențierea primului genom uman, oamenii de știință la nivel mondial au colaborat și au lucrat împreună timp de aproximativ 10-20 de ani, cu un cost total de 3 miliarde de dolari în 2013 (site-ul web al Proiectului genomului uman (HGP): https://www.genome.gov/human-genomeproject).
Concluzie
În prezent, oamenii de știință au nevoie doar de câteva mii de dolari și de câteva săptămâni pentru a finaliza secvențierea unui întreg genom uman. Și se așteaptă ca, în viitorul apropiat, secvențierea unui genom uman să coste doar o sută de dolari sau mai puțin pentru câteva ore. Prin urmare, este de așteptat ca acest cost să fie accesibil. În ceea ce privește accesul aleatoriu și adresarea informațiilor, oamenii de știință au rezolvat această provocare prin conceperea unor primeri unici care să adreseze și să extragă selectiv informațiile necesare. Pentru a evita apariția erorilor, metadatele de corecție a erorilor sunt codificate în fragmente oligo ADN. Între timp, secvențiatoarele de ADN cu o singură moleculă au fost inventate și sunt disponibile în prezent. Acestea sunt la îndemână și portabile. Acestea pot reduce și mai mult costul secvențierii ADN și pot simplifica recuperarea informațiilor ADN. Astfel, în urma progreselor înregistrate în tehnologiile de stocare a datelor ADN, ADN-ul care servește ca mediu de stocare a datelor va fi o oportunitate de aur în această eră a big data.
- Mayer C, McInroy GR, Murat P, Delft PV, Balasubramanian S (2016) An epigenetics-inspired DNA-based data storage system. Angew Chem Int Ed Engl 55: 11144-11148.
- Swati A, Mathuria, F, Bhavani, S, Malathy E, Mahadevan R (2017) O trecere în revistă a diferitelor scheme de codificare utilizate în stocarea digitală a datelor ADN. Int J Civil Eng Technol 8: 7-10.
- Appuswamy RLK, Barbry P, Antonini M, Madderson O, Freemont P (2019) Arhiva: Utilizarea ADN în ierarhia de stocare DBMS. CIDR 2019, Biennal Conference on Innovative Data Systems Research, California, SUA.
- De Silva PY, GU Ganegoda (2016) Noi tendințe de stocare a datelor digitale în ADN. Biomed Res Int pp: 8072463-8072472.
- Panda DM, Baig KA, Swain MJ, Behera A, Dash D (2018) ADN ca dispozitiv de stocare a informațiilor digitale: speranță sau hype? Biotech 8: 9-15.
- Chen K, Kong J, Zhu J, Ermann N, Predki P, et al. (2019) Stocarea digitală a datelor utilizând nanostructuri de ADN și Nanopores de stat solid. Nano Lett 19: 1210-1215.
- Yazdi S, Gabrys R, Milenkovic O (2017) Stocarea portabilă și fără erori a datelor bazate pe ADN. Sci Rep 7: 5011-5013.
- Church GM, Gao Y, Kosuri S (2012) Stocarea de informații digitale de generație următoare în ADN. Știință 337: 1628-1630.
- Kuang SY, Zhu G, Wang ZL (2018) Stocarea de date autoalimentată cu ajutorul triboelectrificării. Adv Sci (Weinh) 5: 1700658.
- Block FE (1987) Teoria calculatoarelor analogice și digitale. Int J Clin Monit Comput 4: 47-51.
- O’ Driscoll A, Sleator RD (2013) ADN sintetic: următoarea generație de stocare a datelor mari. Bioengineered 4: 123-1235.
- Portin P (2014) Nașterea și dezvoltarea teoriei ADN a moștenirii: șaizeci de ani de la descoperirea structurii ADN-ului. J Genet 93: 293-302.
- Leu K, Obermayer B, Rajamani S, Gerland U, Chen IA (2011) Avantajul evolutiv prebiotic al transferului de informații genetice de la ARN la ADN. Nucleic Acids Res 39: 8135-8147.
- Burgers PMJ, Kunkel TA (2017) Furculița de replicare a ADN-ului eucariot. Annu Rev Biochem 86: 417-438.
- Akram F, Haq I, Ali H, Laghari AT (2018) Tendințe de stocare a datelor digitale în ADN: o prezentare generală. Mol Biol Rep 45: 1479-1490.
- Organick L, Ang SD, Chen YJ, Lopez R, Yekhanin S, et al. (2018) Accesul aleatoriu în stocarea datelor ADN pe scară largă. Nat Biotechnol 36: 242-248.
- Bornholt J, Lopez R, Carmean DM, Ceze L, Seelig G, et al. (2016) Un sistem de stocare de arhivă bazat pe ADN. ASPLOS 201 (a 21-a Conferință internațională ACM privind suportul arhitectural pentru limbaje de programare și sisteme de operare, Atlanta, GA).
- Newman S, Stephenson AP, Willsey M, Nguyen BH, Takahashi CN, et al. (2019) Bibliotecă de stocare a datelor ADN de înaltă densitate prin deshidratare cu recuperare digitală microfluidică. Nat Commun 10: 1706-1710.
- Yazdi SM, Yuan Y, Ma J, Zhao H, Milenkovic O (2015) Un sistem de stocare rescriptibil, cu acces aleatoriu bazat pe ADN. Sci Rep 5: 14138-14140.
- Ahn T, Ban H, Park H (2018) Stocarea informațiilor digitale în ADN-ul cu citire lungă. Genomics Inform 16: e30-35.
- Bayley H (2017) Secvențierea ADN cu o singură moleculă: Ajungând la fundul puțului. Nat Nanotechnol 12: 1116-1117.
.