Yarn: Nowy menadżer pakietów dla JavaScript – Facebook Engineering
W społeczności JavaScript, inżynierowie dzielą się setkami tysięcy fragmentów kodu, abyśmy mogli uniknąć przepisywania podstawowych komponentów, bibliotek czy frameworków na własną rękę. Każdy fragment kodu może z kolei zależeć od innych fragmentów kodu, a te zależności są zarządzane przez menedżerów pakietów. Najpopularniejszym menedżerem pakietów JavaScript jest klient npm, który zapewnia dostęp do ponad 300,000 pakietów w rejestrze npm. Ponad 5 milionów inżynierów korzysta z rejestru npm, który odnotowuje do 5 miliardów pobrań każdego miesiąca.
W Facebooku od lat z powodzeniem używaliśmy klienta npm, ale w miarę jak rosła wielkość naszej bazy kodu i liczba inżynierów, napotykaliśmy na problemy ze spójnością, bezpieczeństwem i wydajnością. Po próbach rozwiązywania każdego problemu w miarę jego pojawiania się, postanowiliśmy zbudować nowe rozwiązanie, które pomogłoby nam zarządzać naszymi zależnościami w bardziej niezawodny sposób. Efektem tej pracy jest Yarn – szybki, niezawodny i bezpieczny alternatywny klient npm.
Mamy przyjemność ogłosić, że Yarn został wydany jako otwarte źródło, we współpracy z Exponent, Google i Tilde. Dzięki Yarn, inżynierowie nadal mają dostęp do rejestru npm, ale mogą szybciej instalować pakiety i zarządzać zależnościami spójnie na różnych maszynach lub w bezpiecznych środowiskach offline. Yarn umożliwia inżynierom szybsze i pewniejsze działanie przy użyciu współdzielonego kodu, dzięki czemu mogą skupić się na tym, co ważne – budowaniu nowych produktów i funkcji.
Ewolucja zarządzania pakietami JavaScript w Facebooku
W czasach przed wprowadzeniem menedżerów pakietów, powszechne było dla inżynierów JavaScript poleganie na niewielkiej liczbie zależności przechowywanych bezpośrednio w ich projektach lub obsługiwanych przez CDN. Pierwszy duży menedżer pakietów JavaScript, npm, został zbudowany krótko po wprowadzeniu Node.js i szybko stał się jednym z najpopularniejszych menedżerów pakietów na świecie. Powstały tysiące nowych projektów open source, a inżynierowie dzielili się większą ilością kodu niż kiedykolwiek wcześniej.
Wiele z naszych projektów w Facebooku, takich jak React, zależy od kodu w rejestrze npm. Jednak w miarę wewnętrznego skalowania, napotkaliśmy problemy ze spójnością podczas instalowania zależności na różnych maszynach i wśród różnych użytkowników, z ilością czasu potrzebnego na ściągnięcie zależności, a także mieliśmy pewne obawy związane z bezpieczeństwem sposobu, w jaki klient npm automatycznie wykonuje kod z niektórych z tych zależności. Próbowaliśmy budować rozwiązania wokół tych problemów, ale często powodowały one nowe problemy.
Próby skalowania klienta npm
Początkowo, zgodnie z zalecanymi najlepszymi praktykami, sprawdzaliśmy tylko package.json i prosiliśmy inżynierów o ręczne uruchamianie npm install. Działało to wystarczająco dobrze dla inżynierów, ale zepsuło się w naszych środowiskach ciągłej integracji, które muszą być sandboxowane i odcięte od Internetu ze względów bezpieczeństwa i niezawodności.
Kolejnym rozwiązaniem, które wdrożyliśmy, było sprawdzenie wszystkich node_modules w repozytorium. Chociaż to działało, sprawiało, że niektóre proste operacje były dość trudne. Na przykład, aktualizacja pomniejszej wersji babela wygenerowała commit o długości 800,000 linii, który był trudny do wylądowania i uruchamiał reguły lint dla nieprawidłowych sekwencji bajtów utf8, windowsowych zakończeń linii, obrazów nie zgniecionych w png i innych. Scalanie zmian w node_modules często zajmowało inżynierom cały dzień. Nasz zespół kontroli źródeł zwrócił również uwagę, że nasz sprawdzony folder node_modules był odpowiedzialny za ogromną ilość metadanych. React Native package.json obecnie wymienia tylko 68 zależności, ale po uruchomieniu npm install katalog node_modules zawiera 121 358 plików.
Podjęliśmy ostatnią próbę skalowania klienta npm, aby współpracował z liczbą inżynierów w Facebooku i ilością kodu, który musimy zainstalować. Zdecydowaliśmy się zapakować cały folder node_modules i przesłać go do wewnętrznego CDN, aby zarówno inżynierowie, jak i nasze systemy ciągłej integracji mogły pobierać i rozpakowywać pliki w sposób spójny. Pozwoliło nam to na usunięcie setek tysięcy plików z kontroli źródła, ale sprawiło, że inżynierowie potrzebowali dostępu do Internetu nie tylko do pobierania nowego kodu, ale także do jego budowania.
Musieliśmy także obejść problemy z funkcją npm’s shrinkwrap, której używaliśmy do blokowania wersji zależności. Pliki shrinkwrap nie są generowane domyślnie i nie będą zsynchronizowane, jeśli inżynierowie zapomną je wygenerować, więc napisaliśmy narzędzie do sprawdzania, czy zawartość pliku shrinkwrap pasuje do tego, co znajduje się w node_modules. Pliki te są jednak ogromnymi plamami JSON z nieposortowanymi kluczami, więc zmiany w nich generowałyby ogromne, trudne do przejrzenia commity. Aby to złagodzić, musieliśmy dodać dodatkowy skrypt do sortowania wszystkich wpisów.
Na koniec, aktualizacja pojedynczej zależności za pomocą npm aktualizuje również wiele niepowiązanych zależności w oparciu o semantyczne reguły wersjonowania. To sprawia, że każda zmiana jest o wiele większa niż przewidywano, a konieczność robienia takich rzeczy, jak commitowanie node_modules lub wgrywanie do CDN sprawiało, że proces ten był mniej niż idealny dla inżynierów.
Budowanie nowego klienta
Raczej niż kontynuować budowanie infrastruktury wokół klienta npm, postanowiliśmy spróbować spojrzeć na problem bardziej holistycznie. Co by było, gdybyśmy zamiast tego spróbowali zbudować nowego klienta, który rozwiązałby podstawowe problemy, z którymi się borykaliśmy? Sebastian McKenzie z naszego londyńskiego biura zaczął pracować nad tym pomysłem, a my szybko podekscytowaliśmy się jego potencjałem.
Pracując nad nim, zaczęliśmy rozmawiać z inżynierami z całej branży i odkryliśmy, że borykają się oni z podobnym zestawem problemów i próbowali wielu takich samych rozwiązań, często koncentrując się na rozwiązywaniu pojedynczych problemów. Stało się oczywiste, że współpracując nad całym zestawem problemów, z którymi borykała się społeczność, możemy opracować rozwiązanie, które będzie działać dla wszystkich. Z pomocą inżynierów z Exponent, Google i Tilde, zbudowaliśmy klienta Yarn i przetestowaliśmy jego wydajność na każdym głównym frameworku JS oraz dla dodatkowych przypadków użycia poza Facebookiem. Dziś jesteśmy podekscytowani, że możemy podzielić się nim ze społecznością.
Wprowadzenie do Yarn
Yarn jest nowym menedżerem pakietów, który zastępuje istniejący przepływ pracy dla klienta npm lub innych menedżerów pakietów, pozostając jednocześnie kompatybilnym z rejestrem npm. Posiada ten sam zestaw funkcji, co istniejące przepływy pracy, a jednocześnie działa szybciej, bezpieczniej i bardziej niezawodnie.
Podstawową funkcją każdego menedżera pakietów jest zainstalowanie pakietu – kawałka kodu, który służy konkretnemu celowi – z globalnego rejestru do lokalnego środowiska inżyniera. Każdy pakiet może, ale nie musi, zależeć od innych pakietów. Typowy projekt może mieć dziesiątki, setki, a nawet tysiące pakietów w swoim drzewie zależności.
Zależności te są wersjonowane i instalowane w oparciu o semantyczne wersjonowanie (semver). Semver definiuje schemat wersjonowania, który odzwierciedla typy zmian w każdej nowej wersji, czy zmiana łamie API, dodaje nową funkcjonalność, czy naprawia błąd. Jednakże, semver polega na tym, że twórcy pakietów nie popełniają błędów – łamiące zmiany lub nowe błędy mogą znaleźć się w zainstalowanych zależnościach, jeśli te nie są zablokowane.
Architektura
W ekosystemie Node, zależności są umieszczane w katalogu node_modules w twoim projekcie. Jednak ta struktura plików może różnić się od rzeczywistego drzewa zależności, ponieważ zduplikowane zależności są łączone razem. Klient npm instaluje zależności do katalogu node_modules w sposób niedeterministyczny. Oznacza to, że na podstawie kolejności, w jakiej instalowane są zależności, struktura katalogu node_modules może być różna dla różnych osób. Te różnice mogą powodować błędy typu „działa na mojej maszynie”, których odnalezienie zajmuje dużo czasu.
Yarn rozwiązuje te problemy z wersjonowaniem i niedeterminizmem poprzez użycie lockfiles i algorytmu instalacji, który jest deterministyczny i niezawodny. Te pliki lockfile blokują zainstalowane zależności do konkretnej wersji i zapewniają, że każda instalacja skutkuje dokładnie taką samą strukturą plików w node_modules na wszystkich maszynach. Napisany plik lockfile używa zwięzłego formatu z uporządkowanymi kluczami, aby zapewnić, że zmiany są minimalne, a przegląd jest prosty.
Proces instalacji jest podzielony na trzy kroki:
- Rozwiązanie: Yarn rozpoczyna rozwiązywanie zależności poprzez zapytania do rejestru i rekursywne wyszukiwanie każdej zależności.
- Pobieranie: Następnie, Yarn szuka w globalnym katalogu cache, aby sprawdzić czy pakiet, który jest potrzebny został już pobrany. Jeśli nie, Yarn pobiera tarball dla pakietu i umieszcza go w globalnej pamięci podręcznej, dzięki czemu może pracować w trybie offline i nie będzie musiał pobierać zależności więcej niż raz. Zależności mogą być również umieszczone w kontroli źródła jako tarballs dla pełnych instalacji offline.
- Łączenie: Na koniec, Yarn łączy wszystko razem poprzez skopiowanie wszystkich potrzebnych plików z globalnej pamięci podręcznej do lokalnego katalogu
node_modules.
Poprzez rozbicie tych kroków na czyste i deterministyczne wyniki, Yarn jest w stanie paralelizować operacje, co maksymalizuje wykorzystanie zasobów i sprawia, że proces instalacji jest szybszy. W niektórych projektach Facebooka, Yarn skrócił proces instalacji o rząd wielkości, z kilku minut do zaledwie kilku sekund. Yarn używa również muteksów, aby upewnić się, że wiele uruchomionych instancji CLI nie koliduje ze sobą i nie zanieczyszcza się nawzajem.
Przez cały ten proces, Yarn nakłada ścisłe gwarancje na instalację pakietów. Użytkownik ma kontrolę nad tym, które skrypty cyklu życia są wykonywane dla poszczególnych pakietów. Sumy kontrolne pakietów są również przechowywane w pliku lockfile, aby zapewnić, że otrzymamy ten sam pakiet za każdym razem.
Właściwości
Oprócz tego, że instalacja jest znacznie szybsza i bardziej niezawodna, Yarn posiada dodatkowe cechy, aby jeszcze bardziej uprościć proces zarządzania zależnościami.
- Kompatybilność zarówno z npm jak i bower oraz wspiera mieszanie rejestrów.
- Możliwość ograniczenia licencji zainstalowanych modułów i sposób na wyświetlanie informacji licencyjnych.
- Wyświetla stabilne, publiczne JS API z wyabstrahowanym logowaniem do konsumpcji przez narzędzia do budowania.
- Readable, minimal, pretty CLI output.
Yarn in production
W Facebooku używamy już Yarn w produkcji i działa on dla nas naprawdę dobrze. Umożliwia on zarządzanie zależnościami i pakietami dla wielu naszych projektów JavaScript. Z każdą migracją umożliwialiśmy inżynierom budowanie w trybie offline i pomagaliśmy przyspieszyć ich pracę. You can see how install times for Yarn and npm compare on React Native under different conditions, which you can find here.
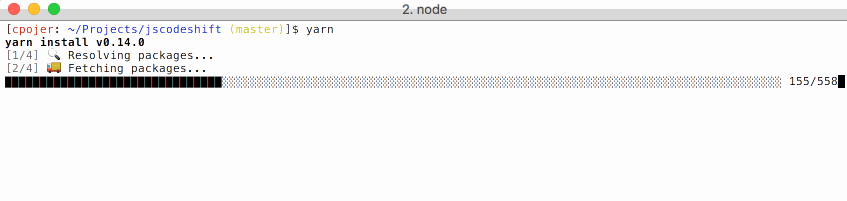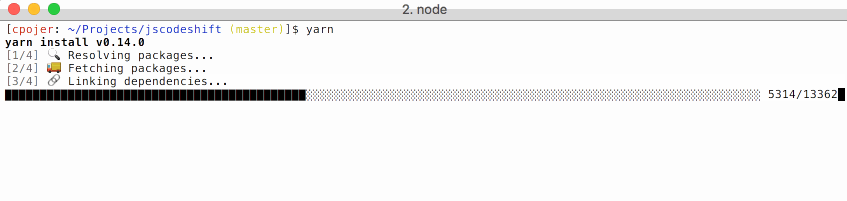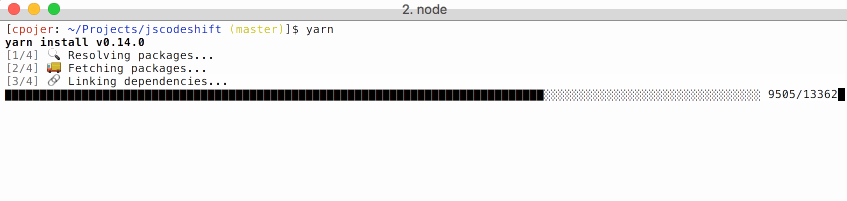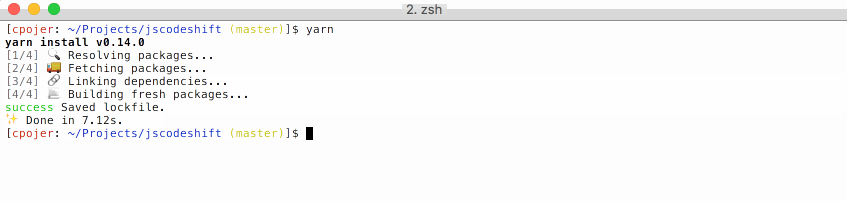
Getting started
The easiest way to get started is to run:
npm install -g yarn
yarn
The yarn CLI replaces npm in your development workflow, either with a matching command or a new, similar command:
-
npm installyarnWith no arguments, the
yarncommand will read yourpackage.json, fetch packages from the npm registry, and populate yournode_modulesfolder. It is equivalent to runningnpm install. -
npm install --save <name>yarn add <name>We removed the „invisible dependency” behavior of
npm installand split the command. Running<name>yarn addis equivalent to running<name>npm install --save.<name>
Future
Many of us came together to build Yarn to solve common problems, and we knew that we wanted Yarn to be a true community project that everyone can use. Yarn is now available on GitHub and we’re ready for the Node community to do what it does best: Use Yarn, share ideas, write documentation, support each other, and help build a great community to care for it. We believe that Yarn is already off to a great start, and it can be even better with your help.